Sun May 31 2026
Agent Memory in an Open World

Two weeks ago, I went to the grocery store to pick up some meal prep ingredients with an AI agent in my ear. I asked it to read off my shopping list, one item at a time, waiting for my confirmation before moving on. Halfway through, it sent me across the entire store because it didn't know that, in this particular Publix, the produce section was nowhere near the dairy. So I started describing the layout as I shopped, and asked it to remember everything.
It did. The next week's shopping trip was pre-organized by the store's actual flow.
That moment is the entire reason this article exists. Grocery store routing isn't a hard problem by any means, but this represented something interesting. My agent learned something specific about my physical world, stored it durably, and used it to make my future life easier. That is what agent memory is supposed to do. And for one narrow domain, on one weekend, it worked!
But getting to that moment took weeks of research and building, and it surfaced a stack of problems I could not solve. What happens when the agent gets confused about which "Publix" I am referring to? What happens when the graph structure deteriorates over time? How do contradictions get caught? What happens when I want to share knowledge with my fiancée, or my team at work, and we have to agree on how information should be structured? The questions kept multiplying.
I talked to some of my teammates at work about this. We went down a logical rabbit hole every other day about how to structure data in a graph that eventually led us to describe exactly what a vector database does, only to then complain about the inefficiencies of vector databases. Around that point, I realized I was rederiving the history of an entire field from scratch. So I stopped and went to read what everyone else had already figured out!
What follows is the full story: the project I built, the wall I hit, the 60-year history of computers trying to store and reason about knowledge, and what I think the pattern of that history tells us about where agent memory is going.
The Project
The system started simple. A while back, a wave of people in the agent space converged on the same idea to use local note-taking tools like Obsidian to build knowledge bases with direct references between nodes. Obsidian works as a basic directory system, where all content is stored in Markdown files. You can include direct links to other notes within the system, and Obsidian even has a nice visualizer to show a graph of all the notes and their connections. Agents are responsible for distilling information into this ecosystem and using it as a means of information retrieval with strong relationships. This is a more elegant solution than the alternatives, and it can be further hardened by something like a proper database for representing relationships and more structured querying.
I created an open-source solution similar to this called KB, which took an opinionated stance of leveraging the Zettelkasten system when structuring notes. This enforced a certain degree of "atomic" notes, with the goal of each note taking up the minimum possible context when consumed, while still being useful.
For my second version, I decided to write a proper service for personal use and expose it as a hosted MCP server with OAuth so my agents could access it across providers and devices. This system had a more robust schema, enabling multiple graphs, tagging, and namespacing. I also made a key observation that I alluded to earlier in this article: the fundamental purpose of this system is to maintain my visibility and ownership of information, while fundamentally transforming the underlying representation to be highly optimized for agentic workflows. In short: stop doing this ridiculous song-and-dance of copying data from a legacy system over to the agent-optimized format. Have everything exist in this format by default and drop the dead weight.
For this to be sufficient, my schema supported generic metadata for each note. This would enable what I called a "plugins" system. I developed a basic user interface to view and interact with graph nodes. However, as noted earlier, this graph interface is practically worthless to me and is, at best, a decent way to audit that the agent is storing information in a reasonable structure. The plugins system allowed me to develop agentic workflows that enforced metadata attachment for particular types of information, which would be used by the client to visually organize information in ways that made it better for human consumption.
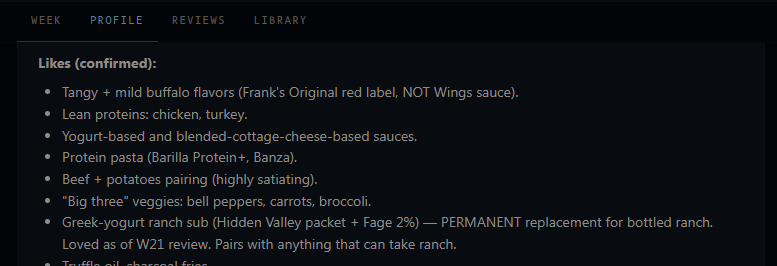
My first use case for this was a "chef mode". This would build a graph of my food preferences profile: foods I liked, disliked, my target calories and macros, and other details about me. Then it would create recipes for me that aligned with my food profile, also stored as a subgraph. You can see an example of this below. I don't manually enter any of this information. The agent will automatically distill statements I make, typically via voice chats, into facts and store them in the knowledge graph automatically. Some of the wording here is really funny. I don't really know why it got so opinionated about Frank's Red Hot specifically not being the wing sauce, but it was likely related to a discussion we had about a recipe we built for some buffalo chicken pasta.
Finally, it distilled the recipe into a grocery list that would be stored in a separate reminders app. This is an important distinction for my knowledge system: store only what makes sense to be long-term information. A grocery list is only useful as a reference, not a long-term memory. The UI would surface this information as a weekly menu.
The dry run
Just like with any new AI-based system, I started out by slamming the agent with a bunch of baseline information about me, my life, my schedule, my goals, and my preferences. The agent did a good job of distilling this information into facts and storing them in the knowledge base. I then tasked it with creating the first recipe for the following week's meal prep. I chatted about wanting something that would fill me up but with fewer calories. Something high volume but low caloric density, and perhaps high in fiber too. It built out a breakfast and lunch schedule for me with a snack in the middle, emphasizing fruit in the morning for a high fiber option. For lunch, the agent found a buffalo chicken pasta recipe. It altered the recipe to include an entire 5oz tub of spinach blended into the sauce, specifically stating it was a low-calorie and high-volume modification that would also be flavorless.
It built me an initial shopping list and organized it by food category. My most surreal experience came when I got to the grocery store. I put in my headphones and began a voice chat. I asked the agent to pull up the shopping list and list off one item at a time until I confirmed that I retrieved it, and move on. As I went through this process, I realized that the agent was going to send me all the way across the store because it did not know that in this particular Publix, the produce section was all the way across the store from the dairy. So I told it that I would be describing the layout of the store as we retrieved items, and asked it to memorize this layout for future grocery lists. I checked the knowledge base later and saw that the agent successfully memorized the layout.

I then came home and did the same thing for the actual meal prep. I had the agent on voice mode, walking me through the recipe as I cooked it. I had doubts about the spinach. It was something I had never tried before at this volume. But it turned out perfect! This was a great success, and all of my goals were achieved. My entire food schedule for the week was grab-and-go. I repeated this process over Memorial Day weekend with a new recipe, and was very happy to see that the shopping list this time around was pre-organized based on the flow of the store. My shopping trip was fast!
This past week, I used this knowledge base system to assist my fiancée and I to plan our honeymoon. Once again, it was fantastic. It was able to store and recall notes about places we wanted to visit, things we wanted to do, and callouts we made for the nuances of travel. I extended the plugins system to support a "document" mode. This still allows the underlying graph system to store information in small segments and facts, but the metadata will preserve order and display context so that the UI can fetch all the subnodes of a root and rebuild them into an ordered document for human consumption. Thanks to this, we have a full itinerary that we have printed out and will use to guide us through our days (although I may prefer to just ask the agent what's on the agenda each day).
Where I Got Stuck
There have been several small issues I encountered along the way that caused the system to hiccup, and I want to call them out so that others trying to replicate this success can avoid them. The first bottleneck was the retrieval speed. I noticed that the agent was taking a while to find information in the knowledge graph because it would query a single keyword per request. After researching other sturdy memory systems like Mem0 and SimpleMem, the simple solution was to expose a bulk query tool that enabled the agent to query for multiple keywords at once. The retrieval was much faster and significantly reduced tool calls. I still had to tweak agent instructions to ensure the agent was not being too verbose with the query text being used. It had a tendency to search for long sentences instead of a simple keyword search.
The second issue was similar in nature: creating memories was 1 tool call per node or edge. This often resulted in hitting the max tool call limit, forcing manual intervention to allow continuation. Yet again, the solution was to enable a "write_subgraph" tool that enabled the agent to create multiple nodes and edges in a single tool call. This resulted in faster write times in fewer tool calls.
The third issue was more of a forethought than something I discovered later. The reality of this knowledge base is that it is only as relevant as my effort to keep it in sync with reality. But I don't want that to be a push mechanism. If something is out of sync, I should probably know about it. This is a tricky problem and required me to think about the different ways information could become out of sync. The first way is for information to change due to circumstances out of my control. These are not necessarily predictable events either. Plans can change from day to day, and it's up to me to ensure that information gets communicated to the agent so it lands in the knowledge base. There is also expected change, and the natural entropy of certain types of information. I can expect that my birthday will never change. In my current stage of life, I can expect that my address may change once every few years. I can expect that the date of my last oil change will go stale approximately every 6 months (if I am kind to my car, at least). This type of staleness can easily be represented through an estimated "stale by" date that the agent sets. The agent is responsible for checking this date and calling out that the information is stale or near stale upon retrieval. I can provide a fact check here, and the agent can adjust the stale date. Other memory systems have a similar mechanism, though they also include a last updated date, so that this is more of a sliding window. I instead opted for a versioning system so that the agent could peek back at old versions.
Things I Could Not Solve
There were some problems that I would keep spinning in circles on. What happens when the agent gets confused about information in the knowledge base? What if I say I want to order a grocery list based on my local Publix, and the agent pulls a different Publix node than the one I expected? What if the agent writes a subgraph in the wrong place? What if the agent does not maintain consistent tagging or naming conventions? What if the graph structure deteriorates over time? What happens to my memory system as it grows? Will the search efficiency degrade? What if I want to share knowledge with someone else, like my team? How does that look? How do I ensure that all our different agents are on the same page about how information ought to be traversed, searched, and structured?
I talked to many teammates about these things, and we came up with some additional considerations, like contradiction detection, truth evaluation, and other things. We talked about Prolog. We went down the logical path on how to structure data in a graph that eventually led us to describe exactly what a vector database does... only to then go back and complain about the insufficiencies of vector databases!
All of this had my head spinning, so I decided to do what any sane person would do and research the history of memory systems. The pattern that emerged surprised me. Every era of knowledge storage has wrestled with the same handful of problems, and every era solved its predecessor's pain points by giving up something the predecessor handled well. The questions I was banging my head against are not new. Most of them have been asked before, sometimes decades ago, sometimes more than once. What follows is the timeline I built, from punch cards through modern agent memory. If you'd rather skip ahead, my synthesis is at the end.
A History of Memory
Long-term memory is not a fully solved problem in the AI space. I went down the rabbit hole of studying the history of this, where we are today, and what approaches are being used. I'll use this section to distill the information.
Punch Cards and Flat Files
Yes, I reached back to the time before RAM for this exploration. This was the era of physical solutions! Punch cards, paper tape, sequential magnetic tape, and my favorite: index cards! I mention index cards because of the famous Zettelkasten system, which organized information into atomic notes containing an ID system that reflected an ordered information graph. I leveraged this in my first knowledge base CLI tool, kb. Others may be doing something similar with Andrej Karpathy's Obsidian Wiki concept. They're all some variation of the Zettelkasten system, which is interesting to see that history has repeated itself! We're starting from scratch on how to organize information, backtracking to first principles.
These systems were sufficient to solve the problems at the time, given technical limitations. They were conceptually simple and cheap. The other machine-based solutions (punch cards, paper tape, and sequential magnetic tape) were also fast for bulk sequential processing. Zettelkasten was not for machines as much as a way for people to organize information for themselves. The pitfall of that system was typically maintenance, drift, supersedence, and the general cost of keeping the notes in line with the current world model. For the machine solutions, there was data redundancy, a lack of data integrity, coupling between applications and data, no ad hoc querying support, and concurrency was effectively impossible without data duplication. Zettelkasten was probably the ideal knowledge base model at the time, but the technical constraints favored alternative solutions.
Hierarchical Databases
A lot of awesome technology came from NASA and the space race era, and hierarchical databases are no different. The NASA Apollo program demanded an inventory system to track all of the parts going into the Saturn V rocket, and the solution was IBMs Information Management System. The data was tree-like in structure. A rocket had stages, stages had components, components had parts, so on and so forth. It was the first widely deployed DBMS, and IBM abstracted storage details behind a query interface (Data Language Interface).
The introduction of schemas and a dedicated query interface was a step in the right direction. It enabled an industrial-scale solution that early enterprises needed, and it is still in production at many Fortune 1000 companies today. People still advocate for its use in modern systems! The concept of tree-like persistence is interesting as it is a step towards a digital Zettelkasten method.
Unfortunately, not all data is a tree. Parts can belong to multiple different assemblies, but trees enforce a single-parent model. Many-to-many relationships ended up being hacky and required manual references. There were technical constraints to the system as well, such as queries being constrained to follow the tree, expensive schema changes, and navigating the tree requiring the programmer to write all the code for it, without automatic query optimization (although, for a young system, this is expected).
Networking Databases
While NASA and IBM were teaming up in the mid-1960s on IMS, Charles Bachman at General Electric built the Integrated Data Store starting in 1962. This used a network model, where records connected via named relationships, and records could have many relationships. The hierarchical model became generalized with this approach, enabling many-to-many relationships. The Conference on Data Systems Languages (CODASYL) standardized this approach in 1969 and 1971. The network database model ended up dominating the 1970s alongside hierarchical systems. Bachman actually won the Turing Award in 1973 for his work. The structure of the information hit the "goldilocks" zone, where the data is represented in a highly flexible yet quickly traversable model that we still use to this day.
Now, the pitfalls. The programmer was still responsible for navigation, just like with IBM's IMS, and it lacked a declarative query language. Schemas were also not truly independent from applications yet, so schema changes broke applications and required code changes across the codebase. Cognitive load about pointer chains and currency indicators also required a deep understanding of the physical data layout, so the abstraction was leaky. These problems are notable for modern agentic knowledge bases. I've found in practice that I care deeply about the network structure. Andrej also had this desire with the Obsidian knowledge base system. The abstraction at this stage of agentic memory is leaky and does not scale well because an indeterministic system is deciding the structure and relationships.
Relational Databases
Edgar F. Codd, IBM Research, published A Relational Model of Data for Large Shared Data Banks in 1970. There were three radical claims made. First, data should be modeled as mathematical relations. Second, applications should be insulated from the physical storage layout. Third, queries should be declarative. This came with three key aspects of data dependence to eliminate: ordering dependence, indexing dependence, and access path dependence. This was a direct attempt to solve problems found within hierarchical and network systems. This was achieved by treating relations as sets and exposing only a high-level query language.
Implementation of this system took a decade, with IBM System R and Berkeley Ingres being the first working relational systems, and Oracle shipping commercially in 1979. SQL was standardized throughout the 80s. By the mid 1980s, relational database systems had replaced hierarchical and network systems as the default choice for new applications. Declarative queries and automatic query optimization were massive improvements over the former, alongside application isolation from data storage concepts. ACID transactions also provided safe concurrency at an industrial scale. The ecosystem buildout made it attractive to a wide audience. It was excellent at processing structured tabular data, which was at the heart of enterprise computing for 40 years.
This system seemed perfect, and it was, for the problem it was solving. As with every technology, this one is optimized for specific behavior at the cost of other behavior. Multi-hop relationships, friend-of-friend, were inefficient. Schema rigidity caused painful database migration concerns. Heterogeneous relationships were awkward to model, resulting in a tangled mess of junction tables or the entity-attribute-value pattern. In the 1990s, when object-oriented programming came onto the scene, translation between objects and rows became a pain point later addressed by ORMs, but not an ideal solution.
Getting into the weeds of knowledge bases, SQL has no native inference. It retrieves rows that exist, but does not derive new facts from rules. There are stored procedures and recursive CTEs that attempt to emulate this behavior, but aren't native solutions. Unstructured data was also a poor fit for the relational database model. Documents, images, audio, and free-form text content can be stored, but relational systems cannot reason about them efficiently.
Logic Programming and "Expert" Systems
This was the first swing at reasoning. Alain Colmerauer and Robert Kowalski developed Prolog in 1972, building on earlier work by John McCarthy on Lisp and on the resolution principle from automated theorem proving. Prolog treated programming as the specification of logical relations. The language allows you to declare facts and rules, then ask queries. The system would search for proofs using unification and resolution.
The 1980s were prime time for what is dubbed "symbolic AI." In 1982, Japan launched the Fifth Generation Systems project, a 10-year effort that poured billions into Prolog-based machines designed to bring expert reasoning to mainstream computing (perhaps we should be wary of overinvestment into modern AI; look at what happened to Japan in the 1990s). Some examples of expert systems include MYCIN, XCON, and DENDRAL. Prolog needed a bridge to the database world, and the solution was Datalog. It is essentially Prolog with restrictions that guarantee termination and tractable complexity. There are no function symbols, bottom-up evaluation, and finite domains. Researchers spent years on the concept of "deductive databases" trying to unify logic programming with relational systems.
Logic programming and expert systems were great at logical inference with formal guarantees, contradiction detection, explainability, declarative knowledge representation, and deep expertise on narrow topics. We can imagine these to be what we are emulating with "skills," "plugins," or dedicated role-based agents today, and we also see the same pitfalls.
Expert systems had a massive bottleneck in knowledge acquisition. Encoding expert knowledge as rules required enormous manual effort from knowledge engineers working with domain experts. Modern LLM architecture has reduced this pain by enabling the experts to write the rules themselves. However, the indeterministic nature of agentic systems, as well as context limitations, maintains a skill gap in "prompting" or "context engineering."
Expert systems also had brittleness around the edges, where they worked well inside their narrow domain but failed just outside of it. We still see this within agentic systems, though it is less obvious. There is a well-known Dunning-Kruger effect when using agent assistants for tasks (actually, it is more akin to automation bias and the illusion of explanatory depth, but Dunning-Kruger is having its run through the community). When delegating tasks to agents that we do not fundamentally understand, the output looks expert-like. We're more likely to blindly accept it, or at least develop a cognitive bias toward believing the agentic system has more intelligence than it actually does. The fix for this is to ask it to do something relatively complex that you understand, and see how confidently wrong it is. LLMs did not fundamentally fix this problem; they just sorta threw more data at it. The introduction of harnesses to create "agents" improved the results through feedforward and feedback mechanisms wrapping the LLM. Stanford's 2026 paper, Meta-Harness: End-to-End Optimization of Model Harnesses, shows that performance improvements can be driven entirely by harness improvements independent of the model being used. Harnesses are sort of like runtime type checking and error handling for a compiled programming language. The LLM is the "compiled knowledge," while the harness allows the LLM to do "runtime checks" on generated artifacts (See: RAG).
There are a few other issues with expert systems. The uncertainty problem prevents success with closed-world model systems that depend on hard facts. Resolution-based theorem proving also has exponential worst-case complexity. It does not scale well. It was terrible to maintain without clear module boundaries, as adding rules to large codebases would create cascading failures. Finally, these symbolic systems were not grounded in reality. Symbols like "cat" were just tokens and had to be supplied externally. Sensor data had to be bridged to symbolic facts, which remained unsolved. The collapse of expert systems was dubbed the second AI winter.
Object Databases and the Entity-Relationship Model
Peter Chen's 1976 paper on the entity-relationship model gave database designers a conceptual tool that would help bridge the gap between real-world modeling and relational schemas. The ER model was not a database, more so a way of thinking. In parallel to this, object-oriented programming naturally spawned object-oriented databases like ObjectStore, GemStone, and Versant, that attempted to eliminate the mismatch between objects in code and rows in tables. The idea was to store objects directly with their relationships, methods, and inheritance intact. Complex hierarchical objects were a nice fit, and traversing object graphs was fast.
The standard never solidified, as each vendor had its own query language. It was tied too closely to specific programming languages like Java, C++, and Smalltalk. Plus, relational vendors added object features and absorbed most of the use cases, and the market ultimately settled on object-relational hybrids mediated by ORMs. This is an interesting case study to consider. The persistence layer was heavily influenced by a particular paradigm, and that paradigm was tethered to particular products. In today's world, I would liken this to harness engineering, where certain things baked into the harness today will be absorbed by the models of tomorrow. Andrew Wilson articulated this in his talk, How to Build Agents That Run for Hours.
The Semantic Web
Tim Berners-Lee, inventor of the World Wide Web in 1989, proposed that the next step should be the Semantic Web: a global knowledge graph where machines could read and reason about content, not just display it to humans. In my opinion, this idea was ahead of its time by a few decades. W3C produced standards to support this, such as the Resource Description Framework, Web Ontology Language, and SPARQL. This was an ambitious attempt to combine symbolic AI with industrial-scale knowledge bases. RDF is conceptually a graph database, while OWL provides description logic, a tractable subset of first-order logic. SPARQL would handle graph traversals and basic inference.
Some real artifacts of the Semantic Web are DBPedia, which extracts structured data from Wikipedia; Freebase, which was acquired by Google, and used to seed the Google Knowledge Graph; and Wikidata, Wikipedia's machine-readable sister project.
While this system was good at standardized representation, formal semantics, federated queries, and schema-on-read flexibility, the system failed to scale and socialize. Manual ontology engineering didn't scale and faced the same bottleneck problem as expert systems. RDF stores were also slow, and the interfaces were awkward compared to the simplicity of REST APIs and JSON. The web ultimately went to JSON instead of RDF. The RDF model of subject-predicate-object triples was also awkward for everyday data and felt over-engineered. Finally, despite attempts to enable reasoning, applied inference through OWL reasoners was expensive and brittle. The same combinatorial issues that plagued Prolog re-emerged.
There were actually different versions of OWL that had varying degrees of combinatorial issues, but did a good job of expressing why the concepts explode. Disjunction, negation, universal quantification, inverse properties, property chains, cardinality restrictions, and equality reasoning are all going to increase the complexity of truth-seeking, especially in an open-world system. Imagine an open world system (if a fact is not stated, it is not assumed false) where disjunction and cardinality are considerations. It is expensive to answer the question: "If a pet is either a cat or a dog, are there exactly 4 pets?" Different versions of OWL will "disable" certain abilities to reduce the complexity. OWL 2 EL, for example, is designed for large but simple ontologies. It has hard constraints that allow existential quantification but forbid universal quantification, disjunction, negation, inverse properties, and most cardinality restrictions. This allows all reasoning to use a forward-chaining algorithm with polynomial complexity. OWL Full, on the other hand, is unrestricted and results in an undecidable complexity. There is no complete reasoner for OWL Full, and there cannot be one. It is used for correct but incomplete answers. But this also makes sense. Every question I ever ask really should be scoped down as much as possible to get a direct answer. Abstraction is a key aspect that these "universal" knowledge systems attempt to bypass, but it is necessary. I'll talk about this in another blog post.
NoSQL and the Return of Graphs
Web-scale companies in the mid-2000s hit limits that relational systems were not designed for. With billions of users and petabytes of data, write-heavy workloads, and geographic distribution, a new solution was needed. Google's BigTable, Amazon's Dynamo, and Facebook's Cassandra papers laid out new architectures that traded ACID for scale. The term NoSQL was coined around 2009 and became an umbrella term for a wide variety of non-relational databases.
NoSQL gave us document stores for semi-structured data, key-value stores for ultra-fast lookups, column-family stores for write-heavy workloads, and time-series databases for monitoring data. The broader lesson is polyglot persistence, where different data shapes call for different storage engines. The era of relational-as-default ended with the onset of NoSQL, even though relational has remained the most common choice.
Within NoSQL, graph databases re-emerged as their own category, with Neo4j popping up around 2000 by Peter Neubauer and Emil Eifrém and shipping publicly around 2007. This generalized RDF triples via the property graph model: nodes connected by typed edges with arbitrary key-value properties on both. Cypher was a nice query language that was simpler than SPARQL. The graph database category grew to include Amazon Neptune, JanusGraph, ArangoDB, TigerGraph, Memgraph, and others.
Graph databases were great at the "friend of a friend" multi-hop traversal. NoSQL databases, in general, have much better schema flexibility than relational databases as well. With graphs, networked data was natural. This worked really well for applications like social networks, fraud detection rings, dependency graphs, recommendation systems, and similar.
Graph databases still fall short in other ways. Aggregations and analytics are slower than columnar relational systems; things like counting, grouping, and statistical operations. Schema discipline is also up to the owner of the graph. It can become a tangled mess if left unchecked. Explicit relationship creation is still a requirement as well, and is something that is an important consideration when building an agentic memory system. Who will maintain edges? This quickly runs into the same problem as the network databases did, where the lifecycle of the data requires you to care deeply about its underlying structure, which is a leaky abstraction. Inference has to be bolted on to graph databases to try to fix this problem, which we will get into later.
Vector Embeddings
Tomas Mikolov and colleagues at Google published Word2Vec in 2013. The paper showed that you can train a neural network to produce dense vector representations of words such that geometric operations in the vector space corresponded to semantic relationships. The common example is "king - man + woman = queen." This did not come out of nowhere and has a long history. There was Latent Semantic Analysis in the 90s, Bengio's neural language models in 2003, and Pentti Kanerva's sparse distributed memory work from 1988. Word2Vec took these early concepts and made them practical at scale.
Trajectory accelerated from here, with GloVe in 2014, contextual embeddings with ELMo in 2018, BERT and Transformer encoders in 2018, OpenAI's text-embedding-ada-002 in 2022, all the way to today's large-context multimodal embedding models. Along the way, simplicity was exchanged for context-sensitivity.
Vector databases emerged to make approximate nearest neighbor search cheap over billions of embeddings. FAISS, Milvus, Pinecone, Weaviate, Qdrant, and Chroma are all examples of vector database systems. We are seeing existing database solutions also absorb vector functionality, which may have similar consequences to the object-oriented database solutions getting absorbed by existing providers, eliminating these specialized alternative systems. Retrieval-Augmented Generation, the pattern of retrieving relevant documents via embedding similarity and feeding them into an LLM, became dominant after ChatGPT came onto the scene in late 2022.
Vector embeddings solved many problems and can be seen as a piece of the puzzle to the current AI summer. It enables semantic similarity without explicit ontologies, something that prevented the success of the Semantic Web. It enables zero-shot retrieval, with no need to build query-specific indexes, an advantage over traditional database systems. It handles unstructured data natively, a major advantage over relational and logical systems. It is also versatile with cross-modal retrieval. CLIP-style embeddings allow you to search images with text queries, for example.
But once again, vector databases are not the end-all, be-all. Precision is still weak, where retrieval will grab topically-similar content that is not necessarily answer-bearing. "Who is the CFO?" returns documents about CFOs and finance, not the specific document that names the CFO. It also has no multi-hop reasoning, as vectors capture similarity in a single space. They miss out on the "A -> B, B ->C" logic since there are no edges to traverse. Temporal awareness is also a problem, which you probably saw in the earlier days of ChatGPT when the training data used was always a year or so behind. Asking for factual data about the world in 2022 produced results from 2021. Contradiction detection is also missing. When loading content into a vector database, chunking the content is very important, but lacks a principled answer to chunk sizing. Updates to a vector database are also expensive. Re-embedding a corpus when the model improves is a major operation. We can almost liken this to the schema challenges of relational databases and database migrations. Finally, embeddings cannot be inspected. You cannot decode embeddings back to text or explain why two items were judged similar, which makes debugging and auditability suffer.
Hybrid Retrieval and GraphRAG
By 2024, three problems with vector retrieval became impossible to ignore. Precision, multi-hop reasoning, and global synthesis. The response was to combine vectors with the structure of graph databases. Microsoft Research published GraphRAG in April of 2024, where a knowledge graph would be extracted from a corpus using an LLM, cluster the graph into communities via the Leiden algorithm, generate LLM summaries of each community, and answer queries by combining vector retrieval with graph traversal and community summaries. In October of that year, DRIFT search added a hybrid local-global pattern, and in November, LazyGraphRAG deferred summary generation to query time, cutting index costs.
In parallel to GraphRAG, the concept of Agentic RAG emerged. Self-RAG trained models to emit reflection tokens that evaluated their own retrievals. Corrective RAG added a separate retrieval evaluator that triggered re-retrieval when results were deemed inadequate. HippoRAG explicitly modeled the hippocampal indexing theory of memory using personalized PageRank over a knowledge graph. RAPTOR built recursive trees of summaries. This is the closest published implementation of hierarchical abstraction over a corpus.
Hybrid systems combine vector recall with graph structure, giving semantic similarity for unknown queries and graph traversal for known relationships. They handle global and local queries like asking for high-level document details as well as specifics like "what did Cameron say?" They can also detect and recover from retrieval failures via agentic loops and have audit trails via graph traversals, where embedding searches fall short.
There are still gaps in hybrid systems. Indexing cost has returned as a problem. Building a knowledge graph with an LLM for every document is an expensive process, similar to the expert systems and their problem of populating facts. Perhaps information is just expensive, and we need to stop acting like it can be made inexpensive. Speaking of which, schema drift is also a problem for graphs, dependent primarily on prompt engineering and model behavior, which are both indeterministic mechanisms. There is still no native contradiction detection in this system, either, and detecting contradictions steers into the logical complexity of negation, which was explored by OWL and the Semantic Web as well as Prolog and Logic systems. Finally, latency continues to be a problem. We have a fun time calling it "thinking," but it's multi-step retrieval, which is slower than vector lookups.
Dedicated Agent Memory Systems
Once LLMs became useful enough to power agents that operate across many sessions, the question shifted from "how do I retrieve from a static dataset?" to "how do I remember and reconcile what I have learned across time?" In October 2023, MemGPT framed agent memory as an operating system problem with core memory in the context window, archival memory in external storage, and the agent itself paging information in and out via function calls. A wave of dedicated products followed. Mem0 was founded in late 2023 and built a hybrid vector-plus-graph memory layer with LLM-mediated rewriting on ingest. Zep leveraged its 2023 Graphiti engine to make bi-temporal knowledge graphs the foundation, with valid-at and invalid-at timestamps on every node and edge, enabling principled contradiction handling. Letta (formerly MemGPT) productized the OS-style design. Other players include Cognee, LangMem, Cloudflare Agent Memory, OMEGA, Supermemory, and Hermes Atlas.
The cognitive science framing came from Princeton's 2023 CoALA paper, which distinguished working, episodic, semantic, and procedural memory and gave the field a shared vocabulary. The first widely used benchmark, LongMemEval, measured single-hop, multi-hop, temporal, knowledge-update, and abstention performance. Mem0's ECAI 2025 paper established the first broad head-to-head benchmark across the category.
Agent memory adds several benefits. Persistence across sessions means conversations and observations from historical sessions can affect the behavior of the current session. The system now also has a reconciliation strategy for when facts conflict with what is already in the knowledge base: overwriting, versioning, invalidation, or flagging are all options here. Personalization is also a factor, where each user gets their own memory separate from other users' memories. Multiple memory types have their own retrieval patterns and storage, between the four layers defined in the CoALA framework.
These systems are still relatively young, so the test of time will tell all. But there are still perceived shortcomings. First, long-horizon factual consistency will still be a problem over the years of accumulated interactions. This is a problem for any system, but there still needs to be a solution. Cost and latency at scale are also problematic. Insertion, retrieval, and reconciliation all require an LLM to do work, which is expensive. Provenance and trust are also concerns when sources disagree. There is no principled way to pick the right one. Selective forgetting and right-to-be-forgotten compliance over a vector store is also operationally messy. CCPA, GDPR, how does data removal work? Do we just ask the agent to forget all the vectors related to someone and make no mistakes? And what about cross-agent memory? Most systems are single-agent, and shared organizational memory with permissions is largely unsolved. What happens when an agent knows about your internal team data and is responsible for sending external emails? How can it know that the internal team data is not to be shared in emails to customers?
The Current Landscape
As of mid 2026, the current popular approach to memory is a multi-layered architecture comprising:
An append-only episodic store as the ground truth and audit-trail
A vector index for semantic recall
A knowledge graph with temporal annotations for structural reasoning
Community summaries or hierarchical abstraction for global queries, often considered the "synthesis" layer
An optional constraint or verification engine for catching contradictions. This is less common in production systems but is part of a concept called Neurosymbolic AI, which was supposedly used in Amazon's Rufus shopping assistant bot.
A context-assembly layer that selects and formats material for the LLM.
Long context models with 1M+ token windows have made simple RAG patterns obsolete. If your knowledge base fits, send it. But the long context did not kill memory. Dynamic data, personalization, cost at scale, and the lost-in-the-middle attention problem all keep retrieval relevant. The 2026 approach is still hybrid, where we will retrieve the most relevant 50-200K tokens and send them to a long-context model.
Reasoning models (most recently GPT 5.5, Opus 4.8, DeepSeek v4) push multi-hop work into the model's "thinking" trace rather than the retrieval system. Memory systems that expose retrieval as a tool and can be called iteratively by the model will benefit the most, while others that treat memory as a one-shot context assembly system fall behind. Mem0's API direction, Letta's architecture, and Zep's structured retrieval interfaces all move in this direction.
For verification, neurosymbolic AI continues. LogicLM in 2023 demonstrated LLM-to-solver translation for faithful reasoning. CLOVER in 2025 added compositional translation. ProbLog, Markov Logic Networks, and DeepProbLog, offer a more principled foundation for probabilistic constraint handling, but have not yet been integrated into mainstream production memory systems.
Open Questions
The current landscape has several open questions that need to be answered. How can we handle long-horizon factual consistency at years-long-interaction scale? How can we make multi-hop reasoning over memory cheap and reliable? How can we integrate principled probabilistic reasoning with the production memory stack? How can we handle provenance, source credibility, and selective forgetting? How can we support cross-agent and organizational memory governance? How can we evolve memory architectures to take real advantage of long context windows rather than working around them?
Analysis
Through exploring the history, I have some key observations with respect to the potential for repeating history.
We already know that resolving logic over a certain network size or within a certain scope over an open world model is not resolvable, and the correct solution to this is to enforce a smaller scope. We benefit from a system capable of making decisions and reasoning about inquiries. We should avoid making the same mistake and leverage agentic systems to push back and break down queries into subqueries that resolve in polynomial time. We already have dynamic programming; this is dynamic reasoning.
We already know that certain problems solved in the short-term will likely be absorbed by entities that make the most sense to own them in the medium-to-long-term. Object-oriented databases in the 90s were entirely consumed by Postgres and other major players. Today, we are seeing a similar pattern, where custom harnesses and memory systems are being integrated directly into the large language models, creating redundancies. Some of these redundancies may be necessary to provide freedom to individuals and enterprises. I imagine that memory systems will need to be portable, as consumers want to avoid vendor lock-in. This may come with a standard protocol to ensure portability, or a business sector devoted to "memory migration" between systems.
Schema migrations from the relational era were a major pain point that stalled the evolution of a system due to the cost of upgrading it. The modern challenge of vector database embedding migrations reintroduces this pain. Even in modern multi-modal systems, the embedding layer is at the core of efficient semantic memory. An evolution of vector systems that can address this problem through anything less than a paradigm shift will likely be absorbed by the existing players in the space, as has happened twice before. One scenario where this may not occur is in a paradigm shift similar to the pivot from relational databases to NoSQL, which spawned a new set of products entirely.
Legacy applications will cause modern systems to be less efficient and more expensive than necessary. Tethering to systems with interfaces that are unfriendly to agentic systems (lack of MCP server, API returning a large number of tokens for a small amount of data) is ultimately going to cost organizations more money on AI spend than necessary. Consider Confluence or Microsoft Word, where page content is monolithic. Tool calls may return the entire text content, despite the prompt asking a "needle-in-the-haystack" type query. Network-like information structures become more important, turning information artifacts into atomic elements that can be retrieved with the smallest possible context footprint. This goes all the way back to the efficiency of the Zettelkasten method.
Modern agentic systems will benefit from graph-like persistence for context-optimized retrieval (I'll dub this one CORe). These systems will still support human oversight, so nodes will maintain metadata that informs the human interface how to reconstruct information (particularly useful for ordered data or shattered content that must be put back together for presentation).
In any future for memory systems, the problem is primarily that of synchronization with the current state of the real world. This will result in an increased dependency on new sensors and actuators that are compatible with, or even native to, agentic systems. We saw some physical devices launch at the onset of the "ChatGPT revolution" in 2023, but these were mostly more efficient interfaces for chatting with agents. The sensors and actuators I describe will need to be active devices, not dissimilar to the surveillance technology Meta is adopting for its employees. Glasses with cameras and microphones, wristbands that can track hand movements, wearables for health data, GPS data, smarthome data, financial data, and more; an open world memory system becomes more successful as it becomes a more active observer of the open world it is representing.
A consequence of this is, yet still, how do we handle provenance and source reliability? When the microphones are always on, but there are blind spots in the information surveillance network, who is to dictate the truth of what is said? What does it mean for the truth to change, and at what point will that change be confident enough to persist in memory?
Regulation will more than likely prevent the system described in the former bullet point from ever existing. We will likely be left with systems that attempt, and fail, to model the open world. The systems that will be fully automated will be those that are almost entirely closed-world problem spaces with repetitive actions that require little to no variation or judgment based on an open-world model. We can see this in China already, with the emergence of Dark Factories, where robots do all the work, so there is no need to even have lights on. Ironically, despite the AI hype cycle indicating the opposite, I believe any job operating inside of an open-world model will still require a significant presence of humans in the loop. This includes critical thinking spaces that require a constant active consideration of the current state of the world, especially in spaces with competing stakeholders. It also includes the obvious social work space, because humans are people and demand that other people, not robots, solve social problems.
In conclusion, I learned a lot about memory systems and their constraints. If you haven't read it before, I recommend reading The Book of Five Rings. The final scroll, Heaven, defines something very important. The most valuable thing to know is what cannot be. It will save you a lot of time. Walking down this path has taught me the theoretical limitations of memory systems and why a full ontological representation of an open world is practically impossible to resolve. Some patterns can be extracted from the previous iterations of memory that can further refine what is worth pursuing or, more precisely, worth avoiding. In general, there are many fun problems to solve in this space. I am excited to see what other creative solutions will come about.